
I built a web app for Chinese language learners to receive daily vocab words, Haohaotiantian.com. In this post, I'll give an overview of how the app works, how I developed it, and the serverless architecture behind it.
Jump to:
About Haohaotiantian
On Haohaotiantian, Chinese learners can subscribe to daily vocab words to build their vocabulary. The name 'Haohaotiantian' is borrowed from a well-known phrase - Study hard and make progress everyday (好好学习,天天上向).
The vocabulary by level (1-6) is from the Hanyu Shuiping Kaoshi (HSK), China's standardized Mandarin testing levels. There are sample words for each level to help users assess their level.
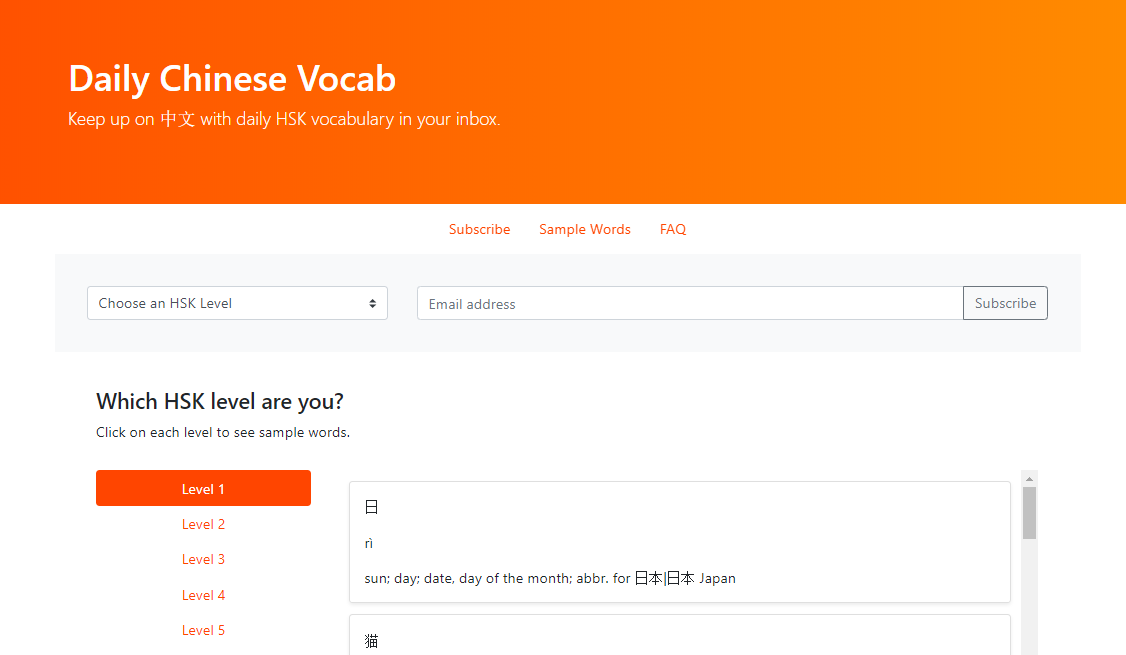
Once a user signs up, vocab words will be sent to their email once a day. Emails look like this:

Levels 1-3 use www.yellowbridge.com for example sentences. YellowBridge has pronunciation audio and character stroke order animations. Levels 4-6 use fanyi.baidu.com which has more complex example sentences.
Users can unsubscribe any time through the links in the confirmation email or daily emails.
Development process
This daily vocab project has evolved and increased in complexity over time. I initially built a much simpler version of the app just for myself, as a way to add reviewing Chinese vocab into my day-to-day routine.
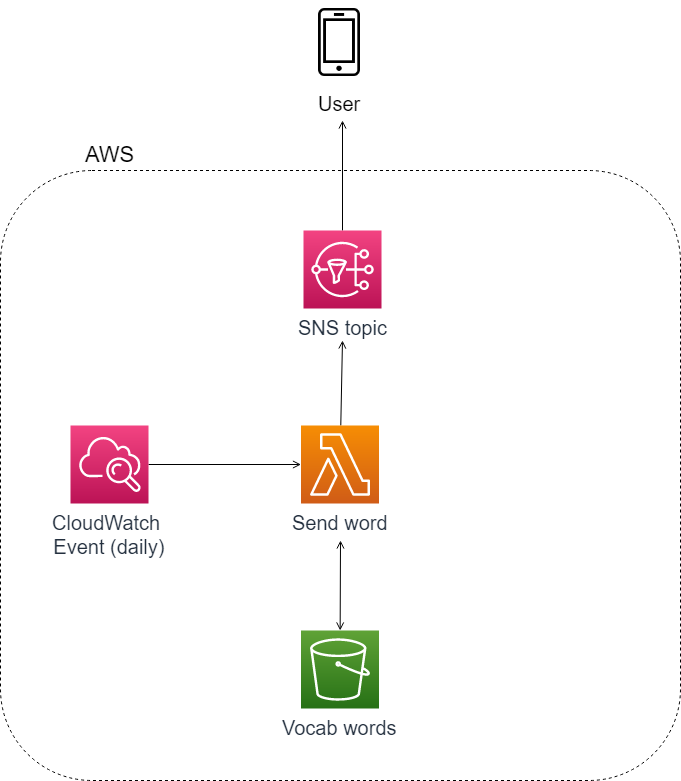
In this early version, I had a daily CloudWatch event rule invoking a simple Lambda function. This function pulled a random word from the vocab list stored in S3 and sent the message to an SNS topic. I subscribed to the topic to get messages as texts, as I found text notifications harder to ignore than email.
In order to subscribe a friend who only wanted level 1 words to the service, I created six different SNS topics and edited my Lambda function to first filter the vocab list by levels, and then loop through those lists and send an appropriate level word to each SNS topic.
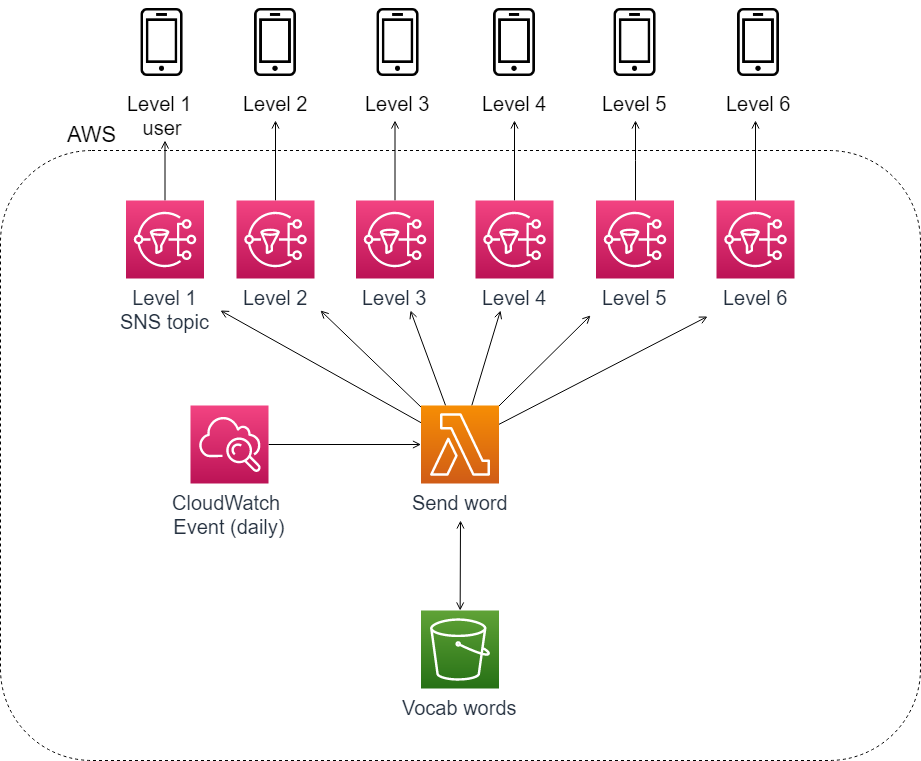
As I got more interest in the service, I decided to move sending messages to users off of SNS. The first motivation was because I wanted to move to primarily sending emails instead of texts for cost. Using SNS pricing as a benchmark, with 50 users per month I would pay $9.03 per month for texts as opposed to $0.01 for email (as of this writing). For a personal project, I am going with emails.
50 users * 30 days = 1500 messages/month
(1500 - 100 free tier texts) * $0.00645 cost/text (in the U.S.) = $9.03 for texts
(1500 - 1000 free tier emails) * $0.00002 cost/email = $0.01 for emails
A second factor was that SNS email subscriptions require email confirmation to subscribe a new recipient. The email comes from 'AWS Notifications' and includes the text,
You have chosen to subscribe to the topic: arn:aws:sns:us-east-1:{topic arn}
which was not end user friendly.
I currently have the app integrated with SendGrid for sending email and managing contact lists. I chose SendGrid for some of the built-in functionality, like contact management and email templates. I may build my own features for these aspects later, but for now offloading them has saved time.
I built in error handling capabilities, such as error handling within the function code to allow functions to continue running if a single API call fails and SNS notifications on failures.
Finally, to fully open the app up to the public and allow users to subscribe online, I created the frontend user interface.
Below, I'll walk through how the current iteration of the app is architected.
How it works
The source code is located here.
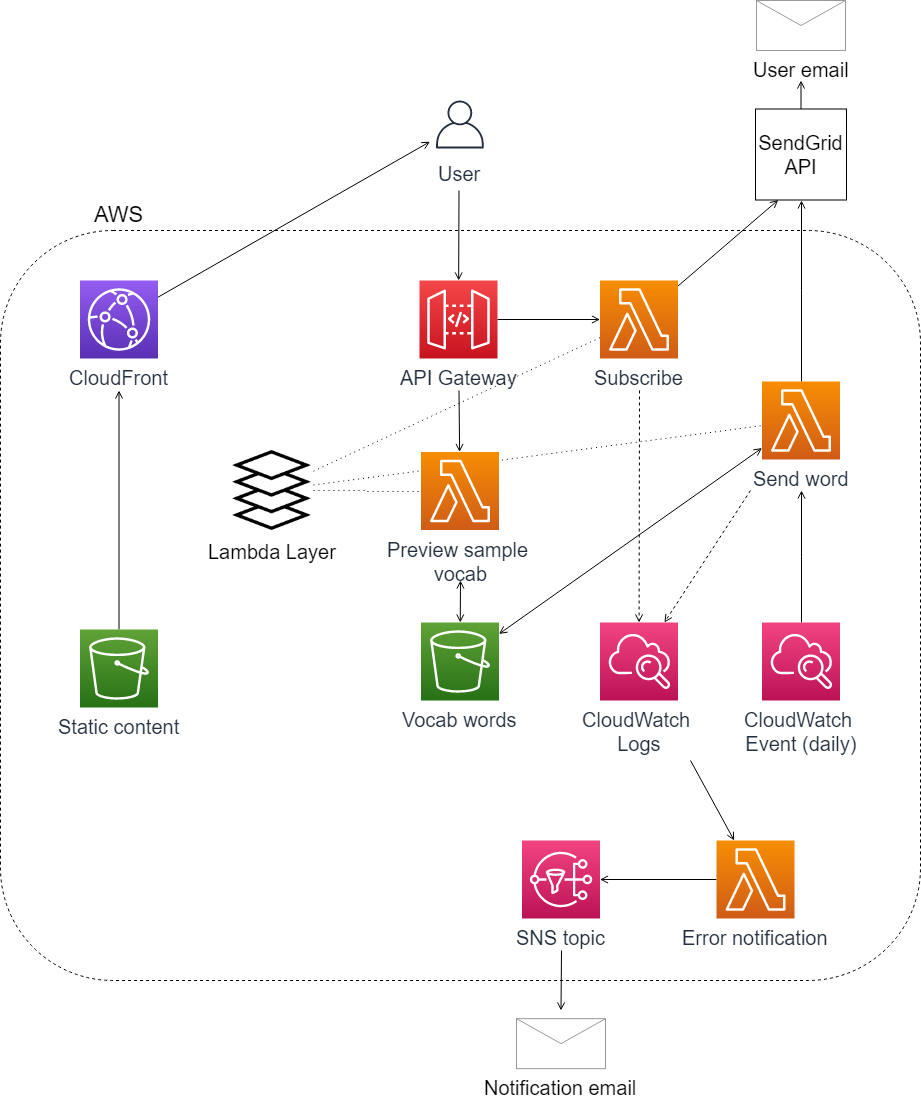
The core functionality of the app is to generate a random word each day for each of the six HSK levels and then send that word to subscribers for that level. The app is primarily AWS Lambda functions behind an API Gateway API and integrated with SendGrid for email. S3 is used for vocab word storage as well as static content, which is distributed through CloudFront.
A user signing up on the website triggers a new user workflow. A Lambda function subscribes the new user by calling SendGrid's create contact API and adding that new contact ID to the SendGrid contact list for the appropriate vocab level. The function then calls the SendGrid API to send a confirmation email.
To trigger the daily vocab workflow, a CloudWatch Events rule is scheduled at 12:00 PM PST each day. This invokes a function that sends the daily email campaign. This function loops through each of the six levels, selecting a random word from the vocab database in S3 and creating and sending a SendGrid email campaign. A failure for any of the levels sends an error notification to SNS, while allowing the rest of the levels to continue to send.
To allow new users to preview words at each vocab level, the web page loads results from an API Gateway endpoint that returns five random words for each level.
For pieces of code that are used by multiple functions, such as generating a random word and pulling the right contact list for a given level, the modules are attached as a Lambda Layer and imported to the functions that use them.
If any of the core functions error out, there is a CloudWatch metrics filter in place that catches error messages. This filter triggers a function that formats the error messages and sends it to SNS.
Learnings
It's been very cool to see this project evolve from a single Lambda function to a full fledged application that's useful to me and other Chinese learners.
Along with the application complexity, I expanded on and increased my depth in the development tools I have been using. I have been working with AWS's Serverless Application Model for a while, and got to experiment with deploying more services (SNS, API Gateway, CloudWatch Events, and CloudWatch Logs) with increased complexity (dependent resources, environment variables) with SAM.
I set up staging and prod environments and a continuous delivery pipeline with GitHub and Circle CI - that's another blog post in itself. Having a deployment pipeline in place has made all the difference in getting away from manually editing functions in the AWS console and moving towards more scalable and faster development practices.
For the frontend, I learned some Javascript to call my APIs and used Bootstrap to make it look nice.
At some point, I made this little Python tool. It converts numerical pinyin (bao1 guo3) to tone marked pinyin (bāo guǒ), pinyin being the romanization system for Chinese pronunciation.
I see opportunities to expand on this project, for example adding in interactivity and spaced repetition for better vocab retention, or adding additional vocab lists for users to subscribe to outside of standard HSK words, like food and cooking or technology vocabulary.
Visit Haohaotiantian.com
Check out the source code
🌻