
One of the top requested features for my daily Chinese vocabulary app was the ability to hear the audio pronunciation for words. To generate audio files from text in bulk, I built a Step Functions workflow that uses the AWS text to speech service, Polly. The workflow generates an audio file for a vocabulary word, saves the audio file to S3, and updates the DynamoDB record for the vocab word with the S3 file location. I'm also speeding up the process of generating audio files for thousands of vocabulary words by processing files in parallel.
Click here for an example audio file: 好好学习,天天向上
You can see the feature live on Haohaotiantian by clicking on any of the orange speaker icons beside the words (screenshot below).

Jump to:
- Background
- Workflow design
- Workflow step-by-step
- State machine definition
- Data flow simulator
- Frontend
Background
When studying a new language, it's helpful to be able to listen to example pronunciation, so it's no surprise many of my Chinese language app users were interested in this feature. It occurred to me that I could use Amazon Polly to generate those audio files. Polly generates mp3 audio files for given text (and vice versa) in several languages.
My app has a vocabulary word bank with several thousands of words that all need audio files generated. My first idea was to write a script to loop through these words and generate the audio files. However, I foresee needing to reuse this workflow as I build new features in my app. For example, in the future I want users to be able to create their own lists, and I will need to provide a way for them to generate audio files for those new lists. With this in mind, I decided to build an automated workflow into my vocab application rather than a one-time script.
Workflow design
My vocabulary words are stored in DynamoDB and grouped by vocab list ID. The full workflow I needed to build was one that would take a vocab list ID as input, query DynamoDB for all the words in that list, call the Polly API to generate the audio file, save that file to S3, and update the DynamoDB record with the S3 key for the audio file so that my app's API responses include the audio file.
Because the task of generating audio for each word can be done independently of the other words, it makes sense to run audio generation tasks in parallel and reduce the time required to loop through the entire word list. I built a Step Functions workflow to orchestrate the different service API calls.
Workflow step-by-step
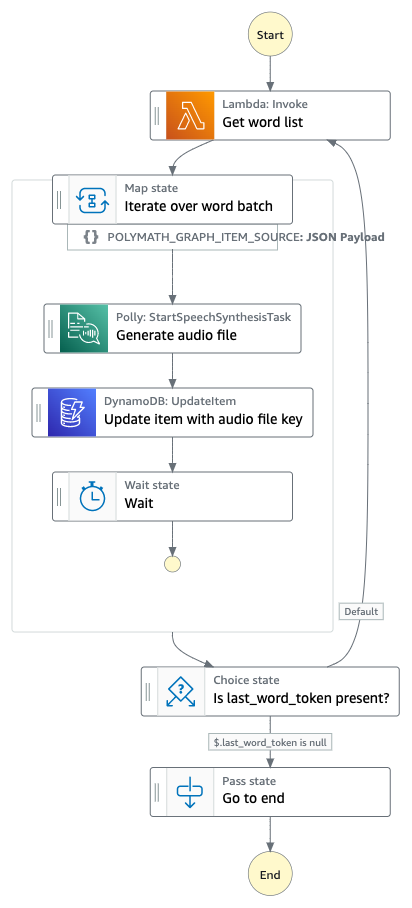
Step 1 My state machine takes a vocab list ID as input when it is invoked (more on the last_word_token below).
{
"input": {
"list_id": "1ebcad3f-5dfd-6bfe-bda4-acde48001122",
"last_word_token": null
}
}
The first step of the audio generation workflow is to query DynamoDB for all the words associated with the vocab list ID. While you can query DynamoDB directly from Step Functions, I've chosen to write a Lambda function for this step. This is because I need to do some reformatting of the data coming from DynamoDB so that it meets the 256 KB limit for Step Functions payloads. The output of this Lambda function is a list of maximum 200 words, with each word containing the DynamoDB primary and sort keys for the word record and the text for audio to be generated from.
In the case of a list that's longer than 200 words, I include a last_word_token for the last word the query returned. Once I complete the workflow, if last_word_token isn't null (meaning there are more words in the list), I'll loop back to the beginning and query for the next 200 words.
Step 2 The second step is to loop through the list of words. For this, I create a map step. I set the max parallelism to 10, which tells my state machine it can generate audio files for up to 10 words in parallel at a time. The reason I set this to 10 is because Polly's StartSpeechSynthesisTask API only accepts 10 requests per second (Polly limits).
Within the map step, the workflow completes these steps:
Step 2.1 The first is to make an API call to Polly. Previously, I would have had to write a Lambda function to make the Polly API call, however Step Functions recently launched an integration with the AWS SDK allowing direct API calls to hundreds of services, including Polly. Now I can call Polly directly from Step Functions which cuts down on the amount of integration code I'm writing.
I include the Polly API call parameters in the step definition, like the text string I want to generate audio for, my preferred Polly voice, and the S3 bucket and prefix to put the file into.
"Generate audio file": {
"Type": "Task",
"Parameters": {
"OutputFormat": "mp3",
"OutputS3BucketName": "${PronunciationAudioBucket}",
"OutputS3KeyPrefix": "audio/",
"Text.$": "$.text",
"VoiceId": "Zhiyu"
},
"Resource": "arn:aws:states:::aws-sdk:polly:startSpeechSynthesisTask",
"Next": "Update item with audio file key",
"ResultPath": "$.pollyOutput"
},
The StartSpeechSynthesisTask API call kicks off the audio file generation task and returns the S3 key where the file will be stored. I added the response from Polly to the state output as pollyOutput using ResultPath.
"pollyOutput": {
"SynthesisTask": {
"CreationTime": "2023-05-03T03:06:17.627Z",
"OutputFormat": "mp3",
"OutputUri": "https://s3.us-east-1.amazonaws.com/{PronunciationAudioBucket}/audio/.3bb2e85c-4724-4e30-930a-5ea5af04757c.mp3",
"RequestCharacters": 1,
"TaskId": "3bb2e85c-4724-4e30-930a-5ea5af04757c",
"TaskStatus": "scheduled",
"TextType": "text",
"VoiceId": "Zhiyu"
}
}
Step 2.2 The second part of the map step is updating the DynamoDB record for the given word with the S3 key for the audio file (which can be found at pollyOutput.SynthesisTask.OutputUri in the state input). Since this operation is simpler than my earlier DynamoDB query state, I can call the DynamoDB PutItem API directly from Step Functions rather than writing a Lambda function. I pass my query parameters (list ID and word ID as composite key) and the update expression for updating the word's audio file key.
{
"Type": "Task",
"Resource": "arn:aws:states:::dynamodb:updateItem",
"Parameters": {
"TableName": "VocabAppTable",
"Key": {
"PK": {
"S.$": "$.list_id"
},
"SK": {
"S.$": "$.word_id"
}
},
"UpdateExpression": "set #w.#a = :audioFileKey",
"ExpressionAttributeValues": {
":audioFileKey": {
"S.$": "$.pollyOutput.SynthesisTask.OutputUri"
}
},
"ExpressionAttributeNames": {
"#w": "Word",
"#a": "Audio file key"
}
},
"Next": "Wait"
}
Now the map iteration for the given word is complete!
Step 2.3 Once all of the iterations for that group of 10 words are completed, I have a wait step in my workflow. This wait step only lasts 1 second and is there to avoid calling the Polly API too many times and hitting Polly's API rate limit.
Step 2.4 After waiting, I loop back to the beginning of the map step and run the workflow for the next 10 words in parallel.
Step 3 Once I've iterated over all 200 words in the batch, I check whether there was a last work token in my original DynamoDB query, and if so I loop back to the very beginning and query for the next 200 words.
This workflow takes about 5.5 seconds to process a word, so a list of 150 words takes 30 seconds and a list of 1000 words takes 3 minutes. The main limitation on speed is the Polly API rate limit and there may be ways to further optimize the workflow overall, but for my use case it's reasonable to ask the user to 'check back later' and have the audio files ready in under 5 minutes.
Tests:
- 148 words, 00:00:29.620
- 1311 words, 00:03:44.730
State machine definition
Step Functions uses Amazon States Language (ASL) to define workflows as code. Rather than writing ASL by hand, I find it easier to use the visual designer Workflow Studio to create the workflow and then export the ASL definition as a file that my Serverless Application Model (SAM) template references.
I put my state machine ASL definition in a separate file from my SAM template since it's long, but you can choose to put it directly in your SAM template. The only change I've made from the exported ASL is adding in a few dynamic references to the other resources (Lambda function, DynamoDB table, S3 bucket), all created by my SAM template.
SAM template
ASL definition
You can see all of the application's code here: github.com/em-shea/vocab
Data flow simulator
I used the Step Functions data flow simulator to understand how to pass data between the different workflow steps. Step Functions uses the JSONPath format for passing data through the workflow. With JSONPath, you can reference variables or reformat the output of a step. Since I hadn't used JSONPath before, I found the data visualizer helpful to debug my input and output data.
Frontend
Now that my vocab word APIs return audio file links for each word, I only needed to make a simple change to the frontend code. I added these <span> and <audio> HTML elements and playAudio() JavaScript method to the "wordCard" component in my Vue.js frontend application. I use this component on a number of pages of my application (review words, user profile pages, and quizzes) If there is an audio file link present in the API response, this code adds a small audio icon that users can click and hear the audio.
<p class="card-text">
{{ card.word.pinyin }}
<span v-if="card.word.audio_file_key" @click="playAudio(card.word.audio_file_key)" class="oi oi-volume-high audio-icon"></span>
</p>
playAudio (audioFile) {
let audio = new Audio(audioFile)
audio.play()
}
And here is a screenshot of the result:
Thanks for reading! I had a lot of fun creating this feature, and I was pleasantly surprised by how easy it was to add a much requested feature to my app.
🌻