
This blog post is Part 1 in a series on refactoring my daily Chinese vocab app to a single-table design in Amazon DynamoDB. In this post, I explain why I chose single-table design, the resources I used to learn it, and walk through the design process and a few example access patterns.
Check out Part 2 where I walk through the process and example Python scripts for migrating to the new data model.
Jump to:
- Why refactor my database architecture?
- Learning single-table design
- Designing my data model
- Final single-table design
Why refactor my database architecture?
The database architecture of my daily Chinese vocab app has evolved over time. In the earliest version of the app, the only data I stored was vocabulary words in a CSV file in Amazon S3. Once I had a more complex database requirements like storing, querying, and updating subscriber data, I began using DynamoDB.
DynamoDB vs. relational databases
DynamoDB is a serverless NoSQL database. Many people are more familiar with relational (or SQL) databases, and there are some important differences between NoSQL and relational databases. NoSQL databases are optimized to query for items by a known key ('Get me user Emily's email and phone number'). When working with a NoSQL database, it's important to plan your application's data access patterns and design your tables around them. With relational databases, you do not need to consider access patterns ahead of time. You can instead use tools like SQL joins to query for whatever combination of data your application needs. With flexible access patterns, though, can come a performance impact, as these complex queries can be slow to run (read more here).
Another key difference is that relational databases are traditionally designed to run on a single server, and scaling beyond a single server's capacity can be an involved process. DynamoDB takes a different approach. DynamoDB scales by breaking data into 'shards' across different servers automatically, allowing it to scale beyond the bounds of a single server seamlessly. This automatic sharding means that your queries must always include the unique identifier (or partition key) for the item you're looking for, so DynamoDB can determine which shard your data is on.
I will confess that when I first started using DynamoDB, I treated it just like a SQL database. I created different tables for each type of data (ex: user subscriptions, review words), organized them in an intuitive and human-readable way, and when my application required it, I joined that data together somewhere in the back end or front end. This worked fine while my application was simple, but as it evolved and I added more features, I started to see the limitations.
Existing database architecture
Up to this point, my application stored data in a few locations:

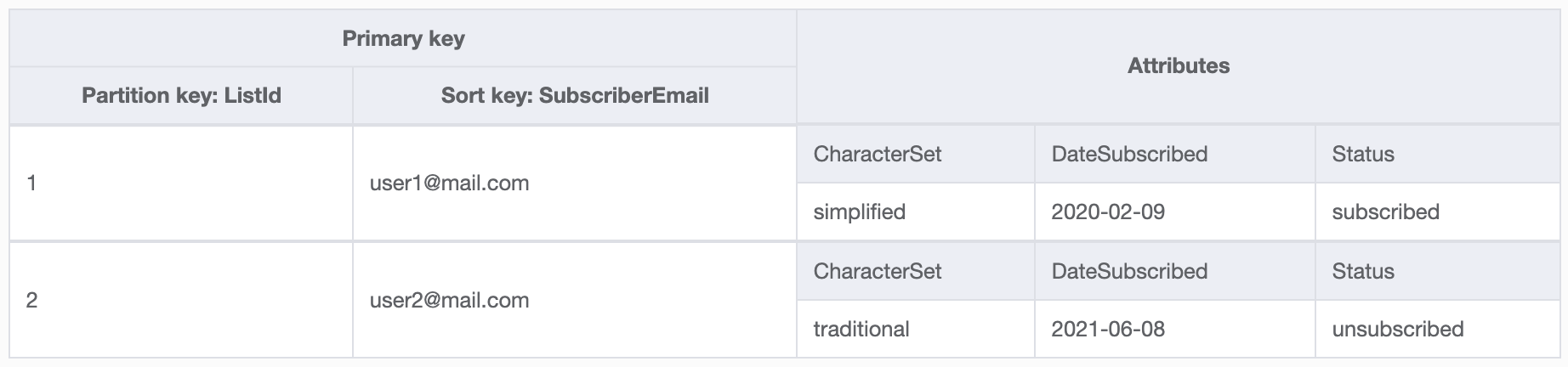
User subscriptions table structure:
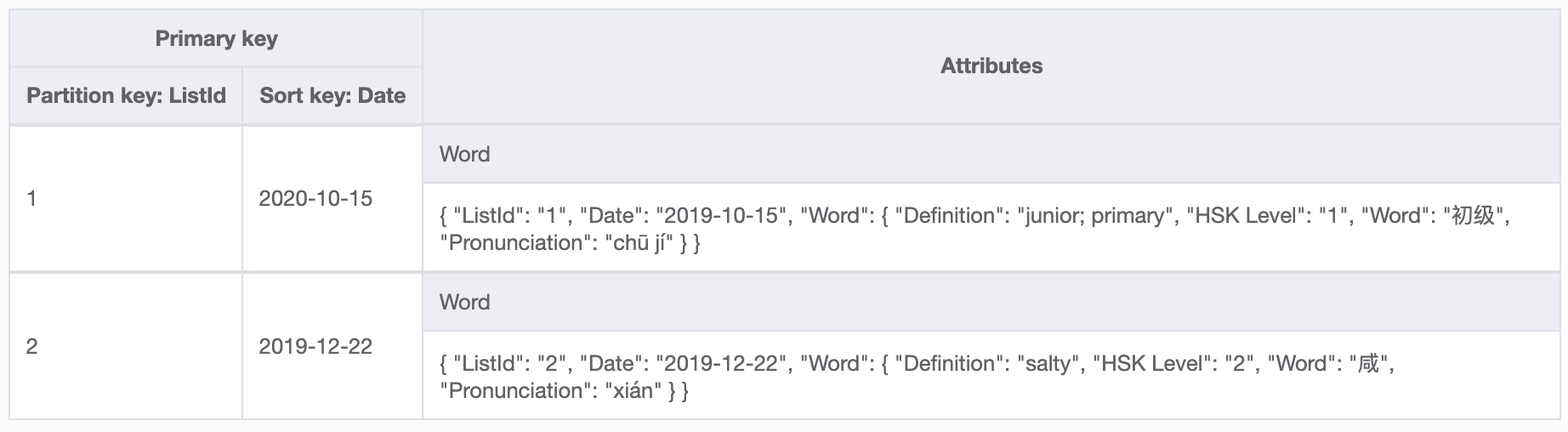
Review words table structure:
Limitations
- Issue #1: Because I hadn't designed my tables with my access patterns in mind, I wasn't able to query for the specific data that new features required. In DynamoDB, you always need to pass an item's partition key (explained more below) in order to query for that item. With my existing table design, the only way to get data for some access patterns (like retrieving all subscriptions for a given user) required doing a full table scan and filtering the results. As your data grows, full table scans become slower and more costly, and so it's wise to avoid them if you can.
- Issue #2: With multiple tables, I needed to join data together. This required multiple API calls to DynamoDB (and additional latency to my users) and more complex application code. By planning ahead and grouping related data together in DynamoDB instead, I can reduce the work required on the application side.
As I looked ahead at the more complex features I wanted to build - like user profiles, practice sentences, and tracking quiz results - I realized that if I wanted to refactor my database design, now was the time before I built more features on top of my existing database structure.
There are multiple approaches to DynamoDB data modelling, one of which is single-table design. The pros and cons of single-table design are discussed in this post. I chose single-table design because I was confident in the access patterns of my application and wanted to make fewer calls to DynamoDB APIs, as well as generally wanting to better understand single-table design!
Designing my data model
Learning single-table design
The first place I recommend for an intro to DynamoDB is the core components section of the documentation. This is a quick read and a good primer on the concepts you'll need to understand when working with DynamoDB.
To learn about single-table design in DynamoDB, Alex Debrie's re:Invent talks (Data modeling with Amazon DynamoDB – Part 1 and Part 2) - and The DynamoDB Book are excellent resources. The DynamoDB Book covers strategies for designing for different entity relationships (one-to-many, many-to-many) and several detailed examples which I found helpful.
Single-table design was a mind bender for me initially. It's such a different approach from the more familiar SQL table design that it took me some time to wrap my head around. I kept making progress on this refactor by:
- Tackling one data type or one access pattern at a time.
- Taking lots of notes on my thought process, because inevitably I'll revisit something and think, 'why on Earth did I make that decision?'
- Mocking up my complete table design in NoSQL Workbench. This is an awesome tool to visualize how your design will lay out in the database. All of the screenshots in this post are from NoSQL Workbench. I regularly reference this mock-up throughout my data migration and as I build new features.
Drawing an entity relationship diagram
To start, I created an entity relationship diagram, or ERD. This helped me understand the different types of data in my application and their relationship to one another.
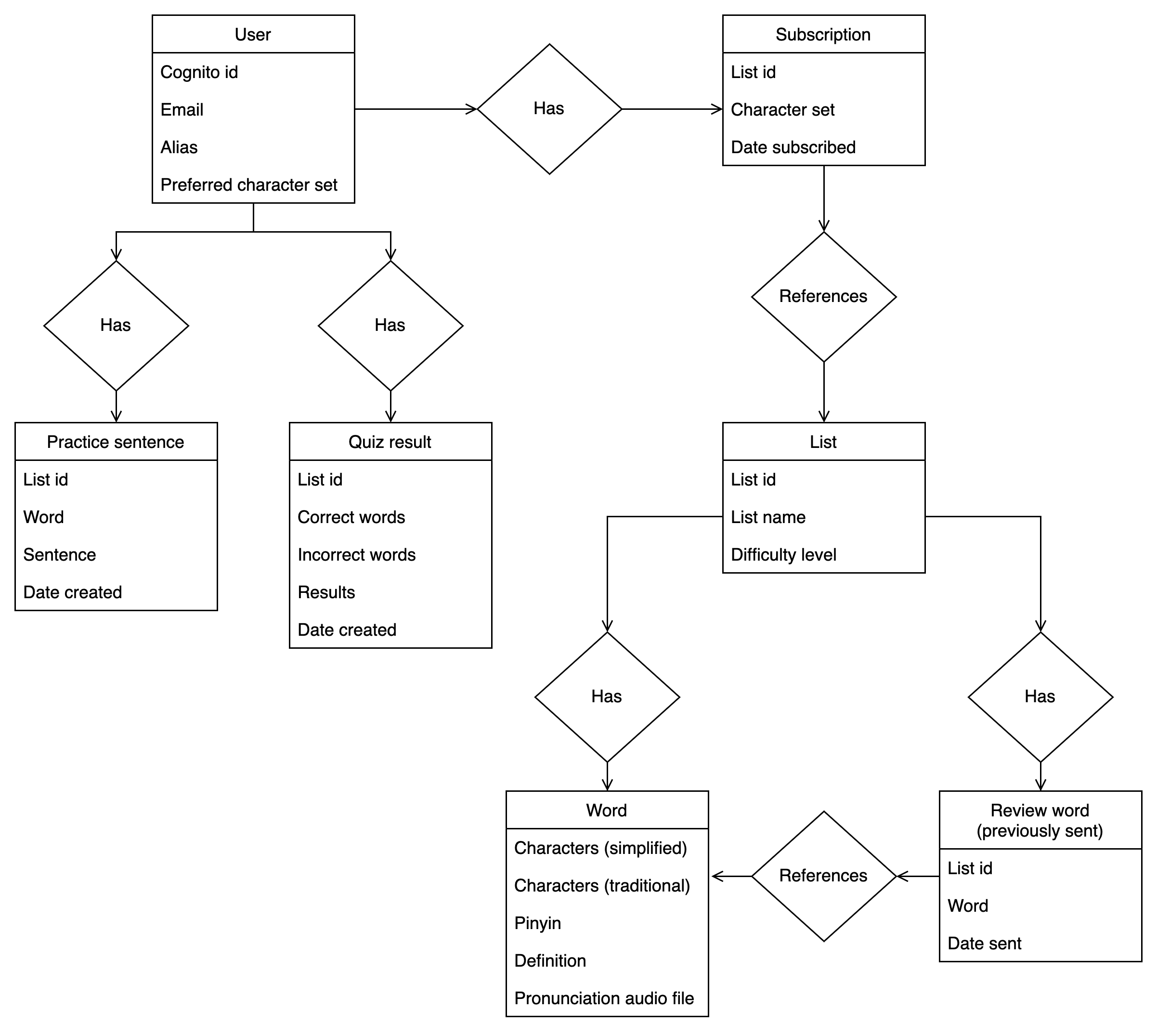
Listing out access patterns
The next step was to list the access patterns of my application. This included my current features and the features I still want to build. The access patterns of my application are:
- User profiles - Retrieve individual user details including subscriptions, quiz results, practice sentences, etc.
- Send daily emails - Retrieve all users and their subscriptions.
- Leaderboards - Retrieve all users' quiz results and practice sentences for a given day.
- Select daily word - Retrieve all words for a given list.
- Review words - Retrieve past words sent chronologically and grouped by list.
- List creation - Retrieve all words (to create a new list).
Below, I'll walk through designing the data model for the first two access patterns.
Selecting primary keys
Now it's time to get into the actual table design! The first step is deciding on primary keys. The primary key is the unique identifier for the items in your database. A primary key can be made up of a single partition key, or it can be a composite primary key with a partition key and a sort key for more granular queries. You always need to know an item's partition key in order to query for it in DynamoDB, so designing good primary keys is critical.
Many of the getting started tutorials for DynamoDB feature table structures that are very human-readable, like this music database (Partition key - Artist, Sort key - SongTitle) or my original table design (Partition key - ListId, Sort key - SubscriberEmail). In order to combine multiple types of data into your database, you're going to need to pack more information into your primary keys, or 'overload' them.
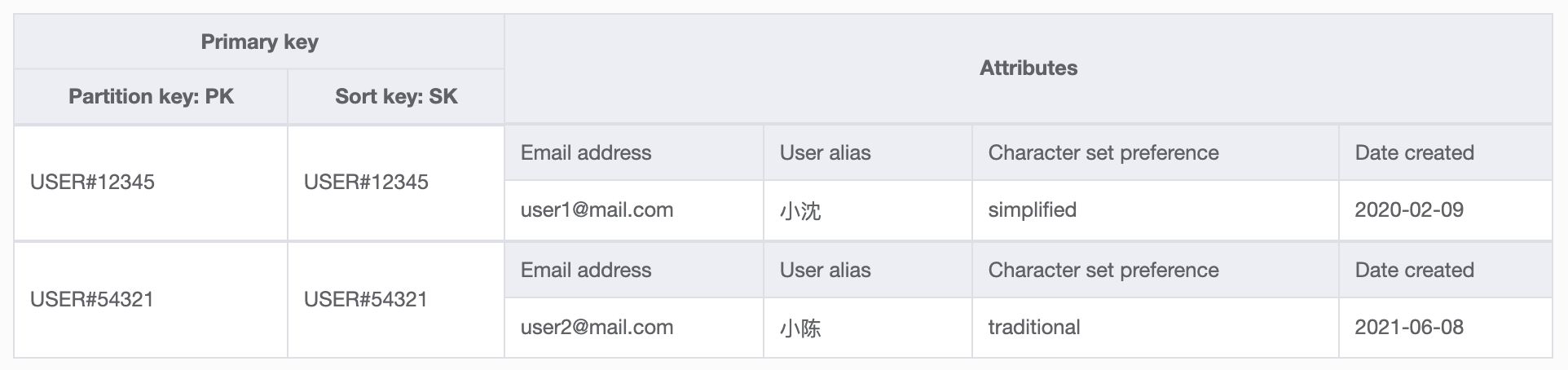
You can do this by setting partition key to the generic PK and sort key to SK and then designing primary keys for different data types (ex, partition keys for users look like USER#12345 and for lists look like LIST#12345). Here is the basic primary key design I created for storing each users' metadata. You might wonder why the PK and SK for user metadata are the same, but you'll see why in the following table screenshot.
Let's expand on this by taking a look at one of my access patterns - generating an individual user's profile page. On a user's profile page, I want users to be able to see all their details - their user name and avatar, their subscriptions, and in the future their quiz results and practice sentences for the past week. This is the user interface I want to create:
In order to pull all of an individual users' items at once, I'm going to group a user's items into an item collection. In a relational database, I would create four separate tables for user metadata, subscriptions, quizzes, and practice sentences, linking them all together with the user ID and joining the data in my SQL query. In DynamoDB, I know that my application will frequently want to retrieve all items for a given user, and so I'm grouping it together by user ID in the database ahead of time. This allows me to query and retrieve the item collection in a single API call.
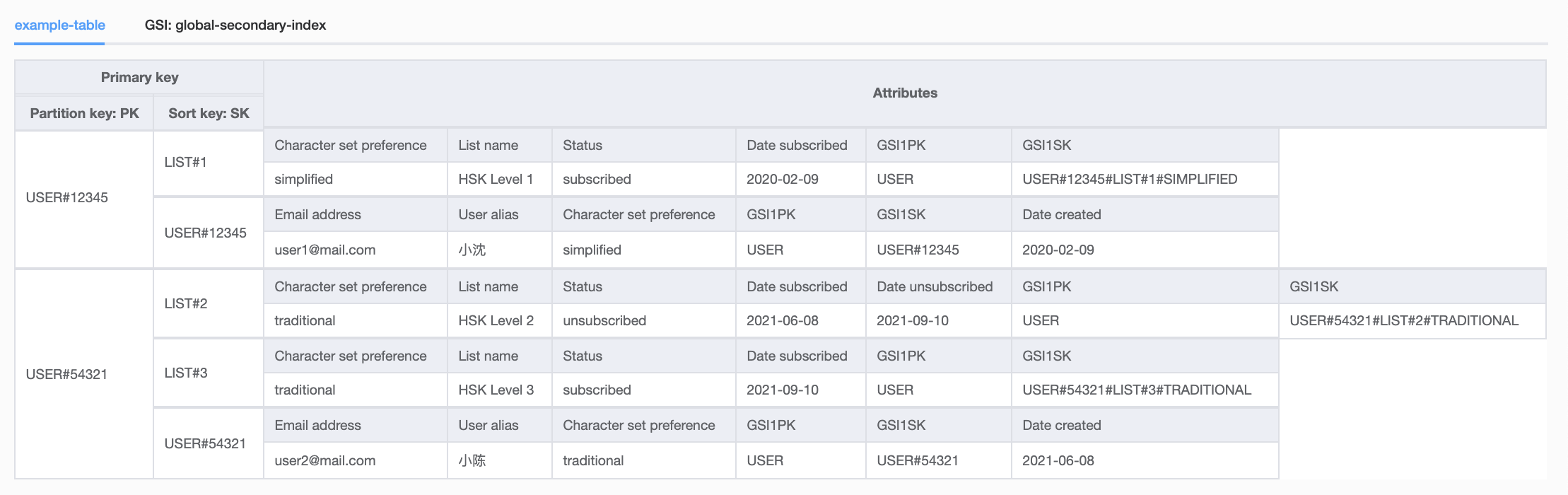
Here is an example table with users and their subscriptions grouped together into item collections:
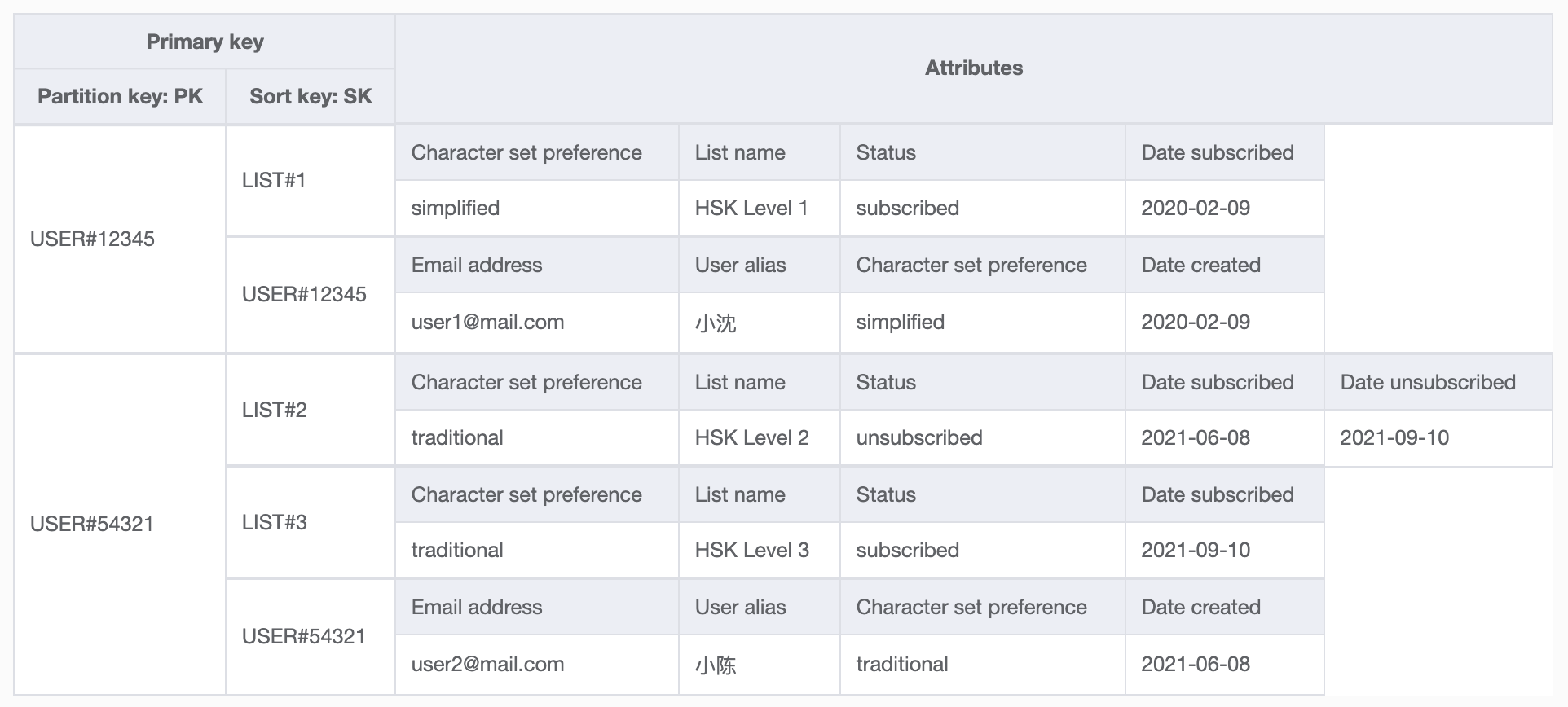
Here is an example query API call to retrieve an individual user's item collection:
table = boto3.resource('dynamodb').Table('MyTable')
response = table.query(
KeyConditionExpression=Key('PK').eq("USER#" + user_id)
)
I've simplified the numerical ids ('123') in these screenshots to save space. Since I'm using Amazon Cognito to manage users, I'm using the user's Cognito ID for the user partition key. For other item's numerical ids, I generate chronologically sortable UUIDs (also called KSUIDs) in order to sort items by date created.
Creating a global secondary index
Now let's think about a different access pattern for the same data set - sending daily emails to all users. In this use case, I need to pull a list of all the users and their active subscriptions in order to send out the daily vocab word emails. Because queries require me to pass a partition key, unless I know every user's Cognito ID when I make the query API call, I can't use the same data model as the last use case.
To be able to add a different access pattern for the same data set, I've used a global secondary index. Global secondary indexes (or GSIs) allow you to choose different primary keys and therefore have different querying options for the same dataset. To retrieve all the users and their subscriptions, instead of grouping data by a user's Cognito ID, I'm now grouping this data by the partition key USER. I'm creating a new sort key pattern where users' metadata sort keys look like USER#12345 and users' subscription sort keys look like USER#12345#LIST#1#SIMPLIFIED (you can start to see how human readability degrades a bit). Now I can pull all users and subscriptions with one query API call.
Here is the same view of the table using the main index, but with new GSI fields (GSI1PK, GSI1SK) added:
Here is the same table, but I've switched the index in NoSQL Workbench to the global secondary index. You can see how the GSI lets me access the same data, just grouped differently with a different primary key:
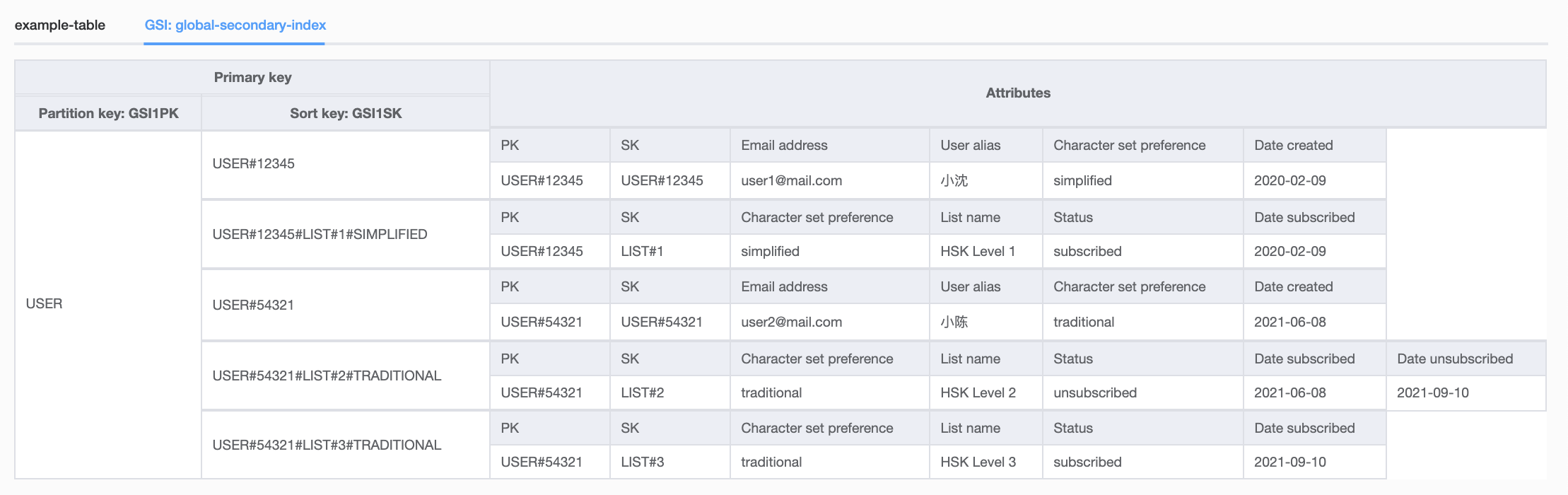
And here is an example GSI query API call to retrieve all users and their subscriptions. The only difference is I now include my IndexName:
table = boto3.resource('dynamodb').Table('MyTable')
response = table.query(
IndexName='GSI1',
KeyConditionExpression=Key('GSI1PK').eq('USER')
)
This would be a long blog post series if I went through every access pattern, so I hope these two examples give you a flavor for planning out access patterns and designing your table. I followed this process for all of my access patterns, took notes on my design decisions, and mocked everything up with sample data in NoSQL Workbench before implementing the changes. I wanted to make sure I hadn't missed anything before getting started on my application refactor!
Final single-table design
Below is the full table design for my daily vocab application (click on the image to expand it). You can also click here to download the JSON and import the data model into NoSQL Workbench.
As with most things in application development, there are lots of solutions to the same problem. While I'm sure there are cleverer ways to design for my access patterns, as a first stab at single-table design, this model fully meets my application's requirements! I also appreciate the deeper understanding I've gained of how DynamoDB works.
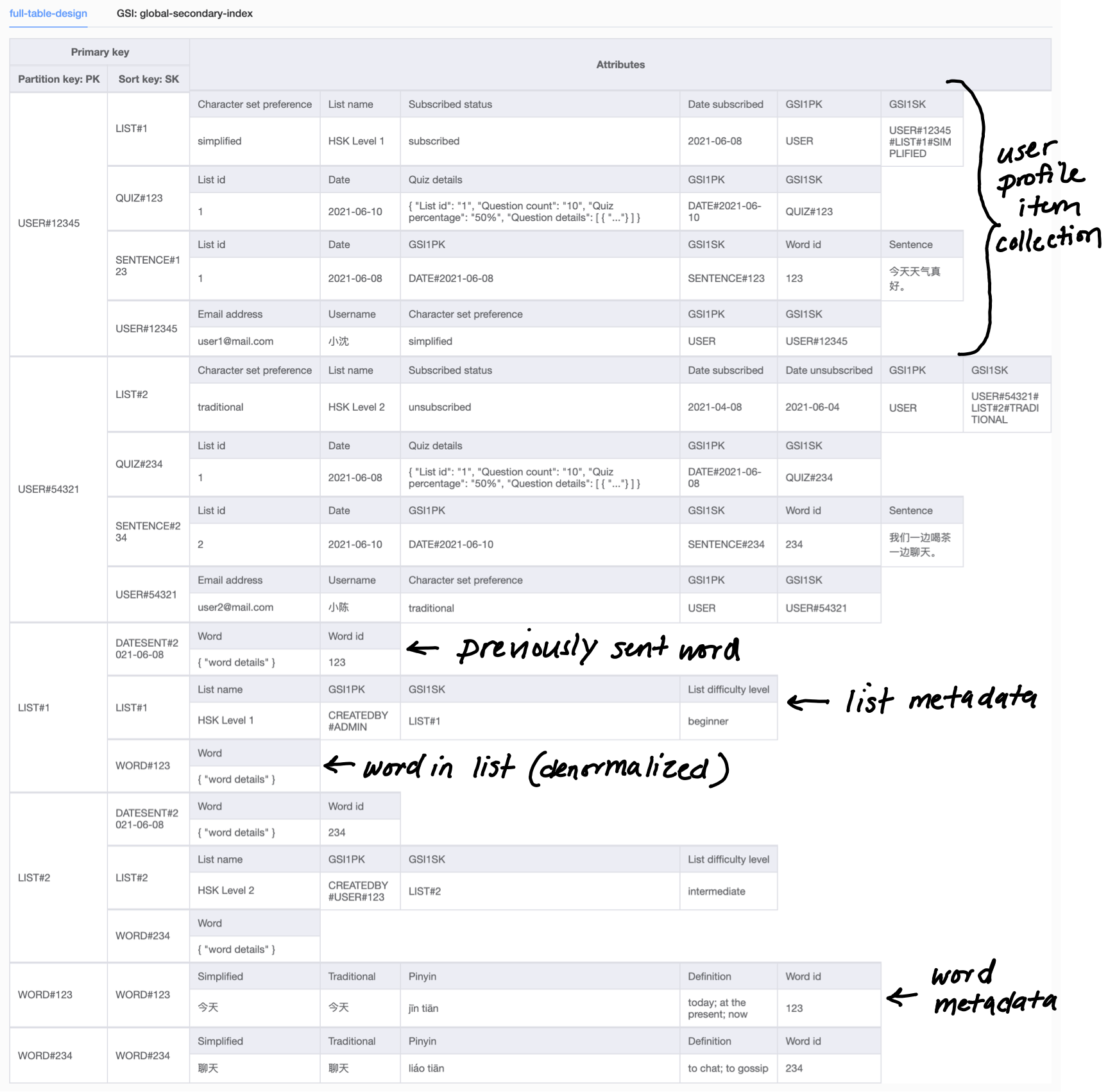
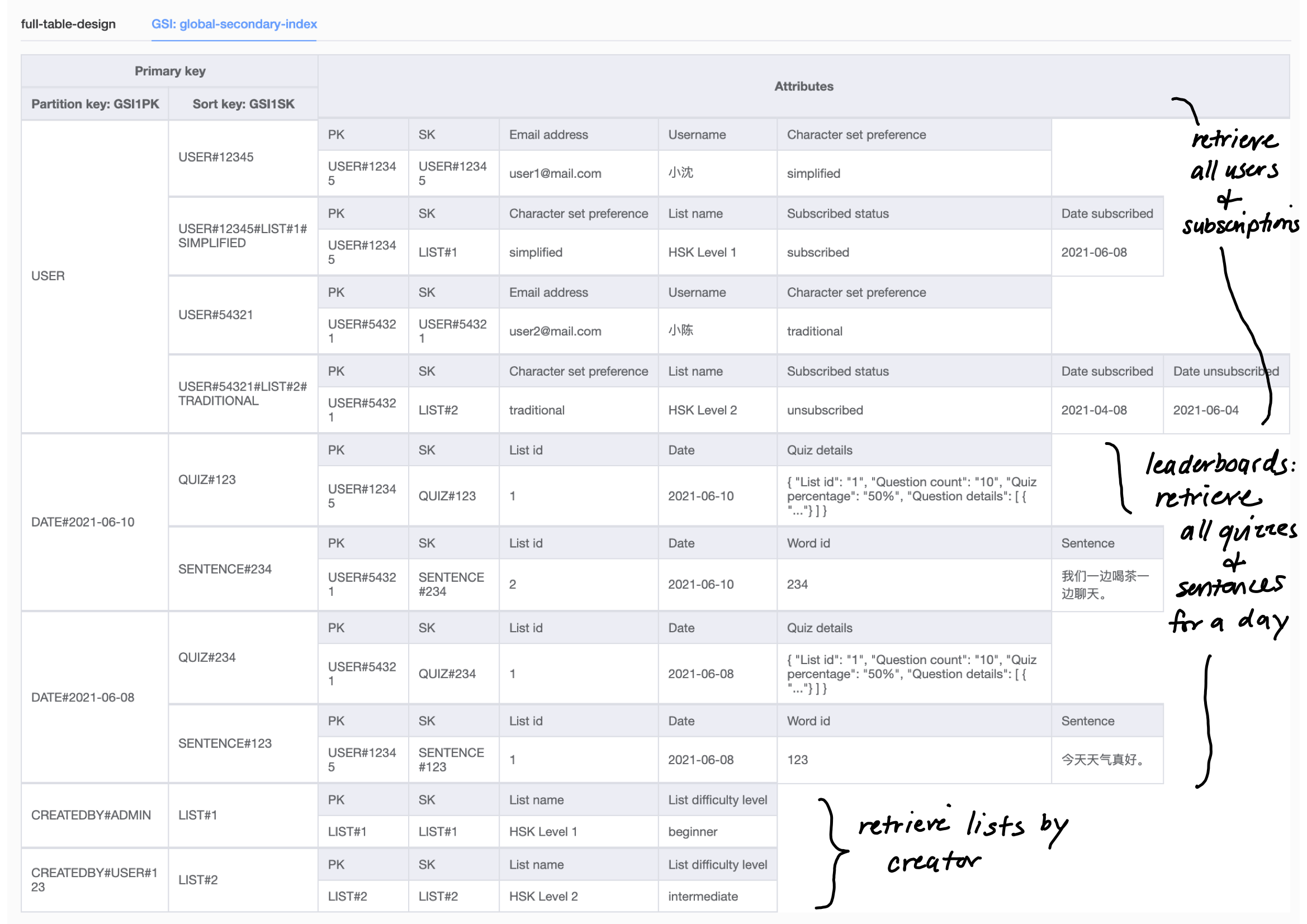
Thanks for following along! Read on in Part 2 where I cover migrating data to the new DynamoDB table design.
🌻