
In my daily Chinese vocab app, I built the ability for users to review past daily words by adding a database. The app sends an email with a vocab word to subscribers daily. The words are pulled at random from one of 6 levels of vocab word lists. In order to keep a record of which words subscribers saw each day and allow users to review vocab, I need to add a database to store the daily words being sent out.
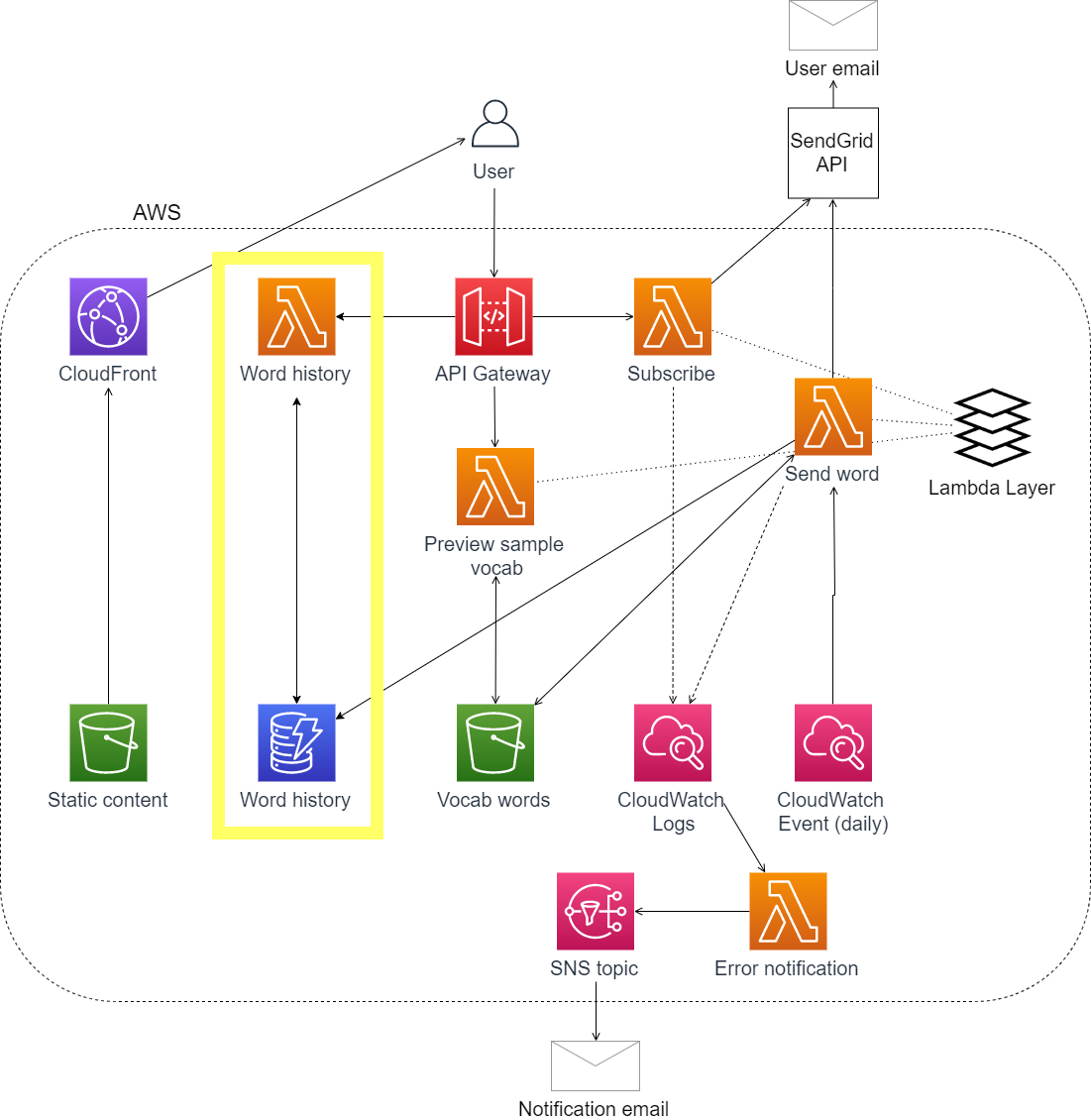
Here I'll share how I designed and implemented my DynamoDB table, including the SAM template I used to define the table, my data structure, and how I integrated it in my Lambda-based application.
Jump to:
Defining the database table
First, let's walk through the SAM template for defining the database table. The SAM template for the full application is here.
DynamoDBTable:
Type: AWS::DynamoDB::Table
DeletionPolicy: Retain
Properties:
TableName: !Sub DailyWordHistory-${Stage}
# cont'd below...
I have deletion policy set to retain so that if I delete my CloudFormation stack, the table won't also be deleted.
To name the table, my SAM deploy command includes a variable for ${Stage} and will create 'stage' and 'prod' versions of the table.
# cont'd...
KeySchema:
- AttributeName: ListId
KeyType: HASH
- AttributeName: Date
KeyType: RANGE
AttributeDefinitions:
- AttributeName: ListId
AttributeType: S
- AttributeName: Date
AttributeType: S
# cont'd below...
This is where we define the unique primary key for each item in the database table. For a quick introduction on key schema concepts, the DynamoDB Core Components docs was helpful.
KeySchema defines the unique primary key for each item and sets which is the partition/hash key and which is the sort/range key. My partition key is the HSK Level list ID ("HSKLevel1") and sort key is the date.
AttributeDefinitions defines the types of data that will be stored in the partition and sort key (both of mine are strings, or 'S'), which combine to form a composite primary key. You need to provide an attribute definition for each key in your KeySchema.
# cont'd...
BillingMode: PAY_PER_REQUEST
ProvisionedThroughput:
ReadCapacityUnits: 0
WriteCapacityUnits: 0
For billing mode, I chose pay-per-request, also called on-demand (and set provisioned throughput to 0). Alternatively, you could set billing mode to 'PROVISIONED' and specify provisioned throughput units. 25 read and 25 write capacity units are within the AWS free tier. At the scale of my project, on-demand should cost something like $0.00025/mo (or essentially free).
Data structure
Each item in my database table is a vocab word that has been sent to users. With just a few lines of code, I can write the word to DynamoDB in the same function that sends the daily email. That function already contains a "word" dictionary that holds the daily word, definition, pronunciation, and HSK level integer.
I'm adding two additional attributes to record the date the word was sent and HSK level list name ("HSKLevel1").

If I was starting over, I would unpack the "word" dictionary and store each item at the same level in the table for easier access.
Application integration
To use the database table in the application, I needed to:
Add code in the Lambda function that sends daily emails to also write the daily words to DynamoDB (function code).
Create an API endpoint and a Lambda function that returns the daily word history for each HSK level (SAM template, function code).
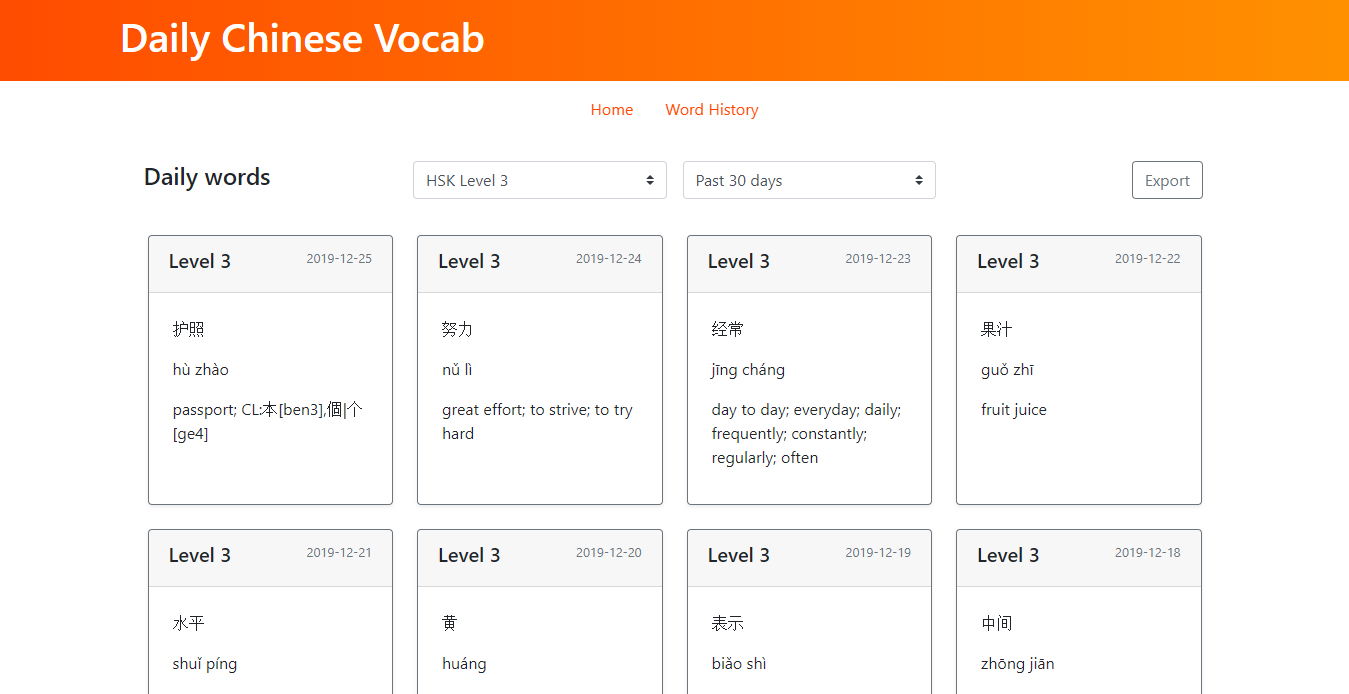
Check out the API endpoint here. It accepts query string parameters for the HSK level and date range (ex, HSK level 3 words over the past 30 days). If no parameters are passed, the endpoint will return the 8 most recent words for all 6 HSK levels.
Build a user interface to surface API results (Vue.js code).
Visit Haohaotiantian.com
Check out the source code
🌻